|
Hi! I'm Divyansh, an Applied Scientist at Amazon working on integrating knowledge graphs with LLMs for enhanced grounding, reasoning, and agentic search capabilities. I received my PhD in Electrical and Computer Engineering from Carnegie Mellon University, advised by Dr. Gauri Joshi. My research focused on efficiently fine-tuning and training ML models on data distributed across individual users (e.g. mobile devices) via on-device training. I aimed to develop both theoretically grounded and practical algorithms that speed-up convergence and improve model accuracy while addressing the communication/computation constraints inherent to such settings. During my PhD, I have had the opportunity to intern at IBM Research (summers 2022 and 2023) and Bosch AI Research (summer 2024) working on problems related to accelerating model training and efficient LLM inference. Prior to CMU, I completed my Bachelors in Technology (B.Tech) in Electronics and Electrical Communication Engineering from IIT Kharagpur, where I received the Institute Silver Medal for graduating with the highest CGPA in my department. |

|
|
Jan 26: Excited to share that our work FlexMerge was accepted to ICLR 26! Sep 25: Our work RAVAN on multi-head federated LoRA fine-tuning was accepted at NeurIPS 25! July 25: Defended my thesis and started working as an Applied Scientist at Amazon! May 25: New preprint on improving robustness of federated LoRA fine-tuning to heterogeneity. Dec 24: New preprint on understanding why pre-trained initialization can dramatically improve performance of FedAvg. May 24: I will be interning at Bosch AI Research, Pittsburgh working on fusing multiple fine-tuned models. April 24: Work on coded over neural networks got accepted to ISIT 2024! Jan 24: Work on one-shot federated learning using Fisher information got accepted to AISTATS 2024! Sep 23: Attended the New Frontiers in Federated Learning Workshop at Toyota Institute of Chicago (TTIC). Thanks to all the organizers! May 23: I am returning to IBM T.J. Watson Research Center, New York as a summer research intern. Jan 23: My internship work on tuning the server step size in federated learning was accepted as a spotlight presentation at ICLR 2023! Oct 22: Work on incentivizing clients for federated learning was accepted as an oral presentation at the FL-Neurips 22 workshop! (12% acceptance rate). Aug 22: Completed my internship at IBM T.J. Watson Research Center, New York. April 22: Our team was selected as a finalist for the Qualcomm Innovation Fellowship for the research proposal "Incentivized Federated Learning for Data-Heterogeneous and Resource-Constrained Clients". |
|
|
|
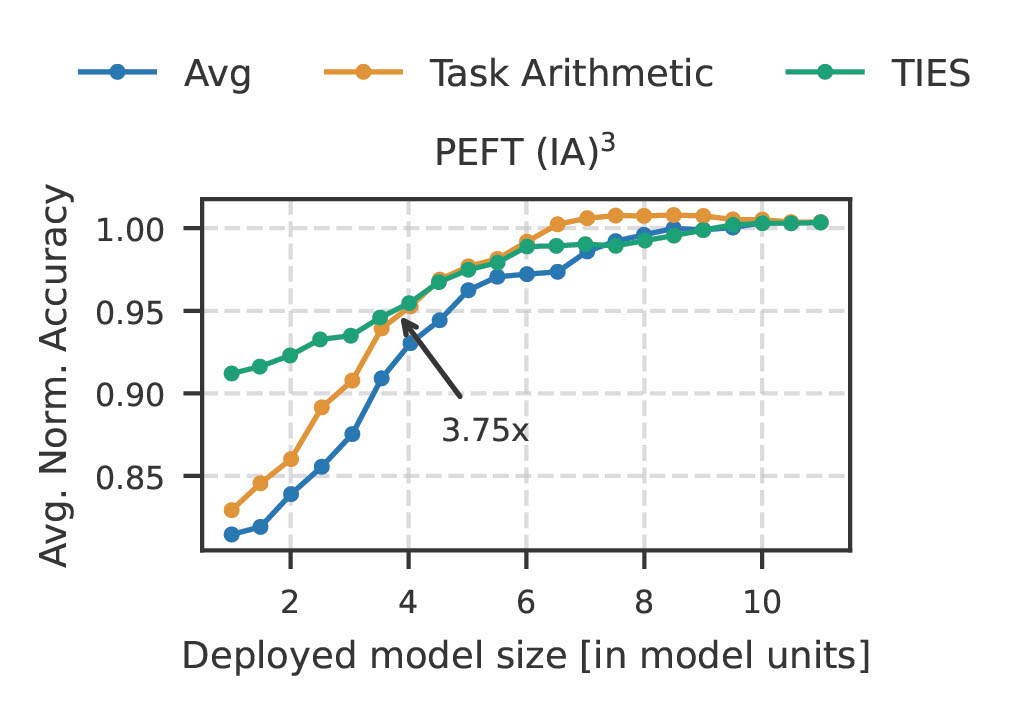
Akash Dhasade, Divyansh Jhunjhunwala , Gauri Joshi, Anne-Marie Kermarrec, Milos Vujasinovic International Conference of Learning Representations (ICLR), 2026 Proposed FlexMerge, a model-merging approach that offers the flexibility to fuse fine-tuned foundation models into one or more models, balancing task accuracy and model size. |
|
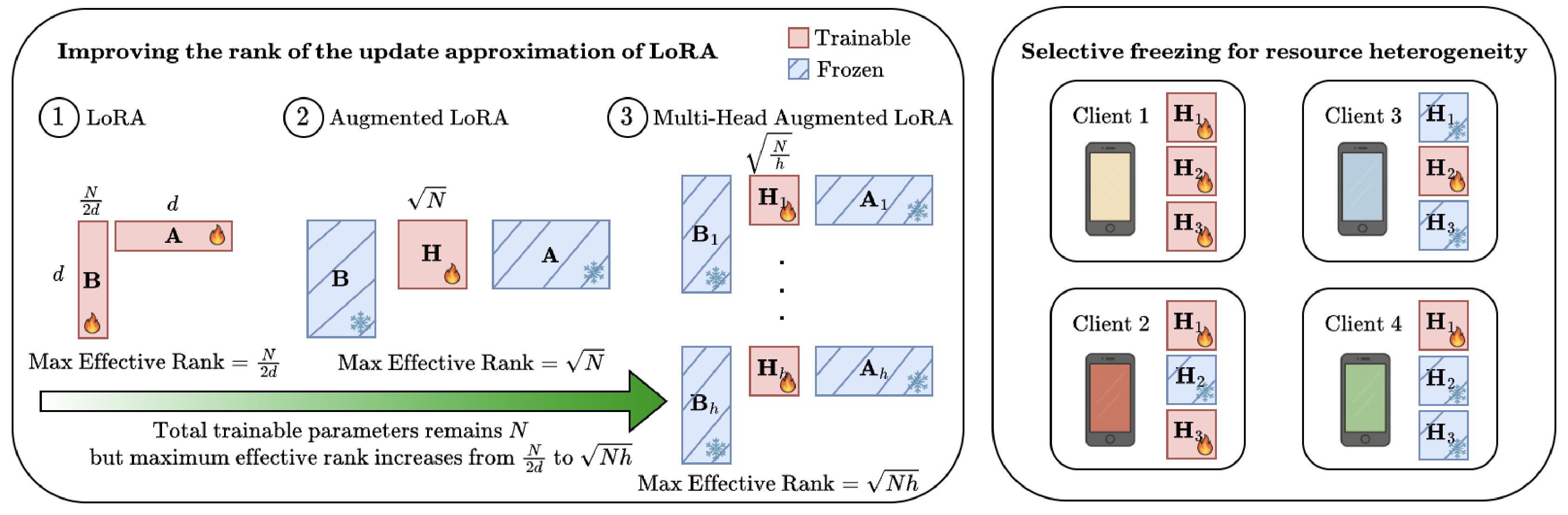
Arian Raje, Baris Askin, Divyansh Jhunjhunwala , Gauri Joshi Neural Information Processing Systems (NeurIPS), 2025 Proposed RAVAN, an adaptive multi-head LoRA method for federated fine-tuning that improves accuracy by 2–8% over prior approaches by balancing parameter efficiency and expressivity. |
|
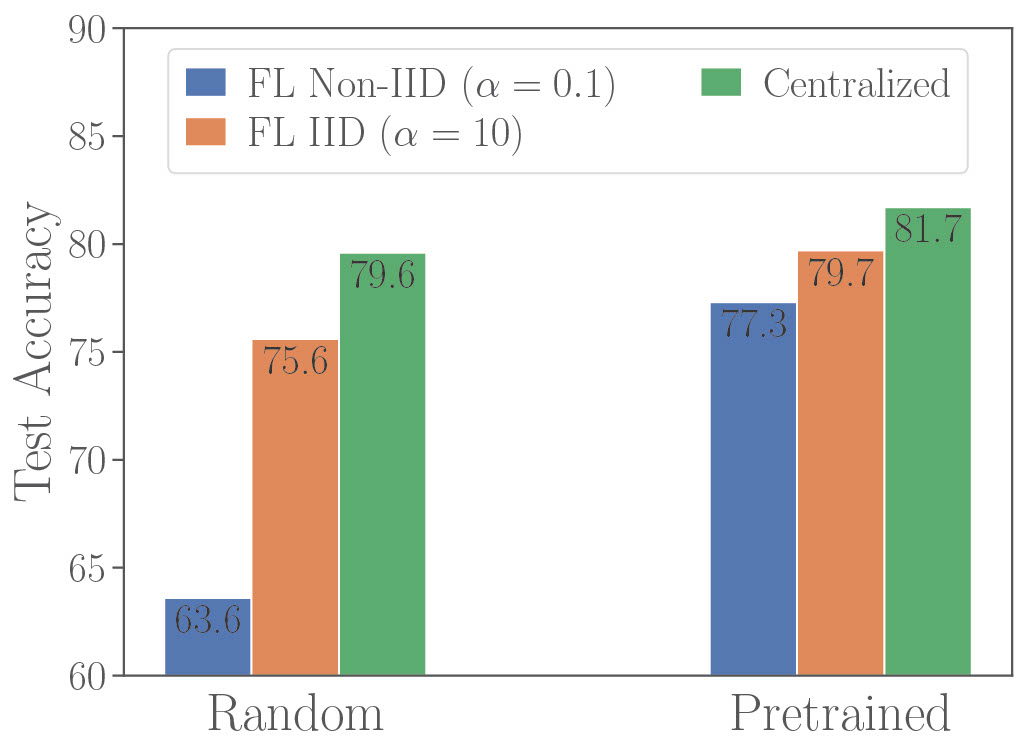
Divyansh Jhunjhunwala , Pranay Sharma, Zheng Xu, Gauri Joshi Transactions of Machine Learning Research (TMLR), 2025 Provide the first theoretical explanation for why pre-training significantly boosts performance of FedAvg by introducing the notion of misaligned filters at initialization and showing that a) data heterogeneity only affects misaligned filters b) pretraining can reduce the number of misaligned filters at initialization. |
|
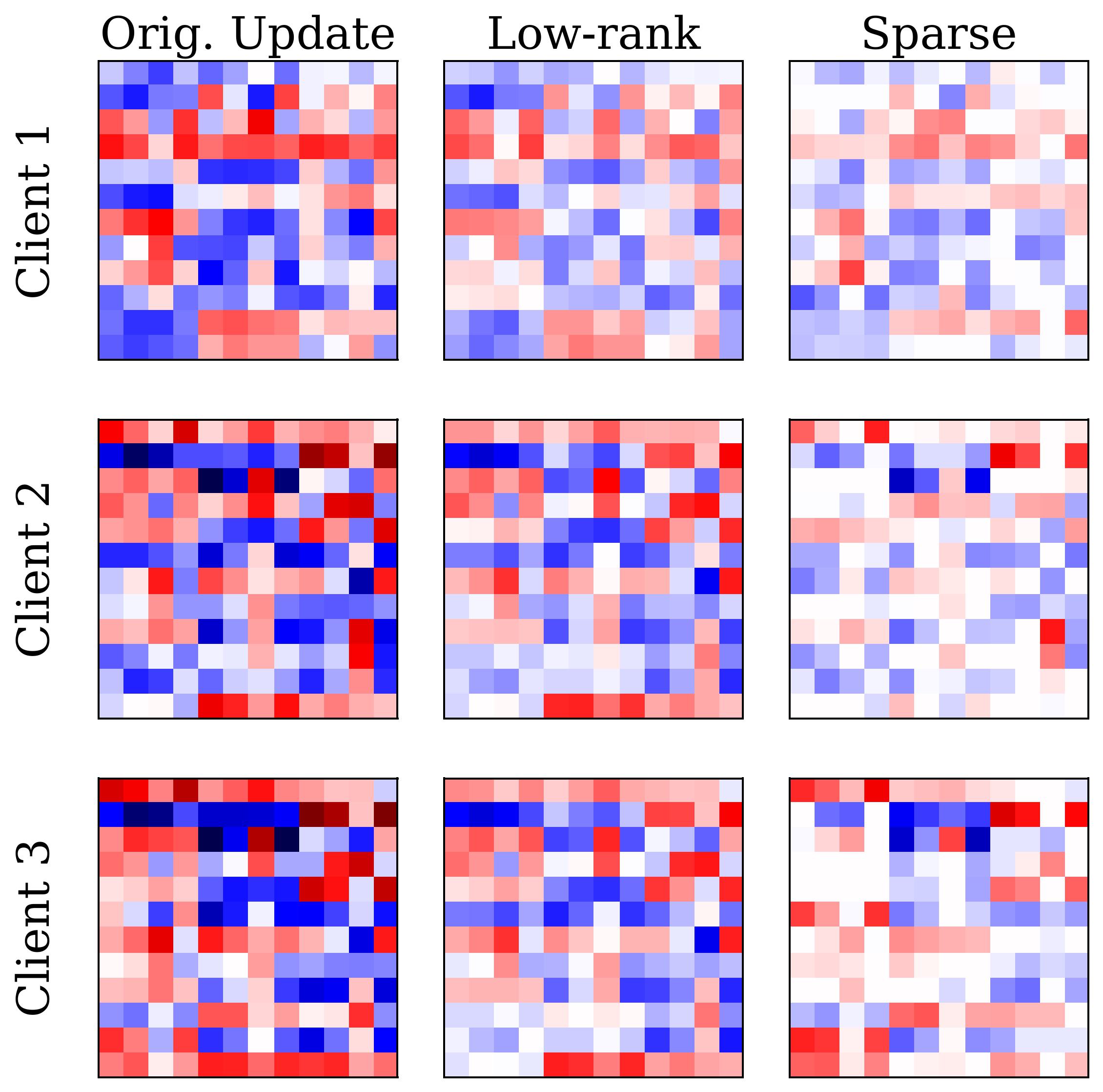
Divyansh Jhunjhunwala , Arian Raje, Madan Ravi Ganesh, Chaithanya Kumar Mummadi, Chaoqun Dong, Jiawei Zhou, Wan-Yi Lin, Gauri Joshi, Zhenzhen Li Under submission Proposed FedRPCA, a Robust-PCA–based aggregation method for federated LoRA fine-tuning that separates common and client-specific knowledge to improve both convergence speed and final accuracy across vision and language tasks. |
|
Divyansh Jhunjhunwala * , Neharika Jali *, Shiqiang Wang, Gauri Joshi IEEE International Symposium on Information Theory (ISIT), 2024 Develop COIN, a model-fusion framework to approximate the sum of outputs of multiple neural networks with a single neural network for handling demand uncertainty in multi-model inference. |
|
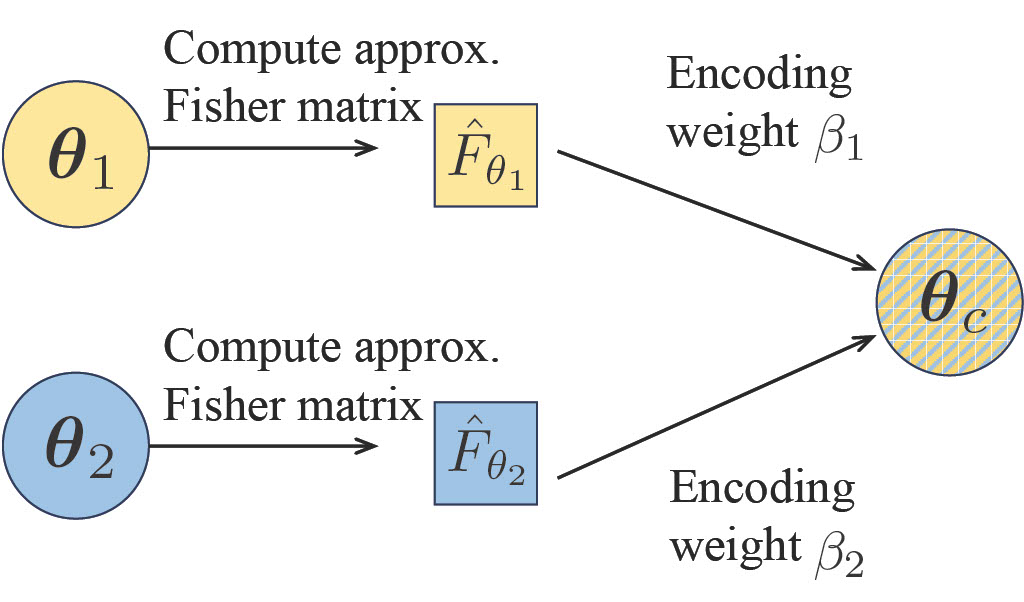
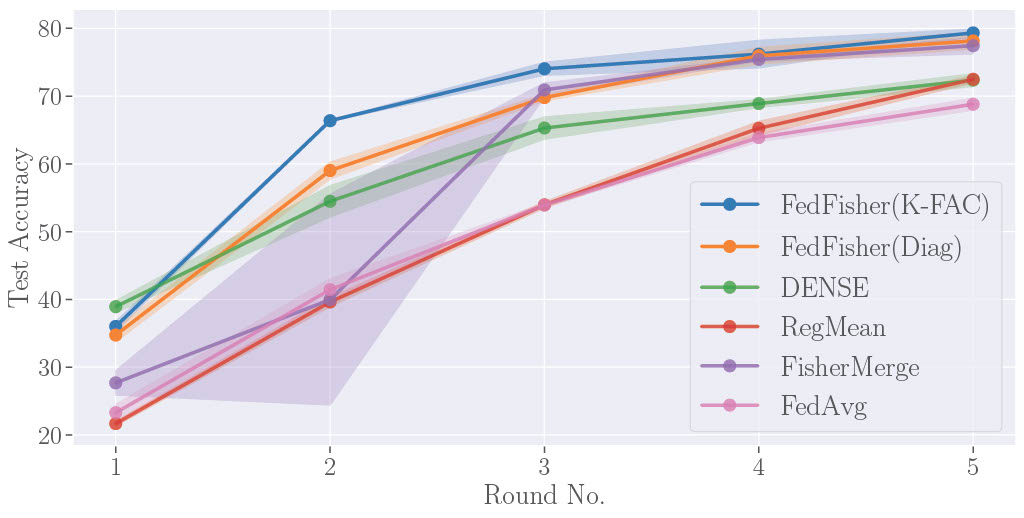
Divyansh Jhunjhunwala , Shiqiang Wang, Gauri Joshi International Conference on Artificial Intelligence and Statistics (AISTATS), 2024 Propose FedFisher, an algorithm for learning the global model for federated learning using just one round communication with novel theotetical guarantees for two layer overparameterized ReLU networks. |
|
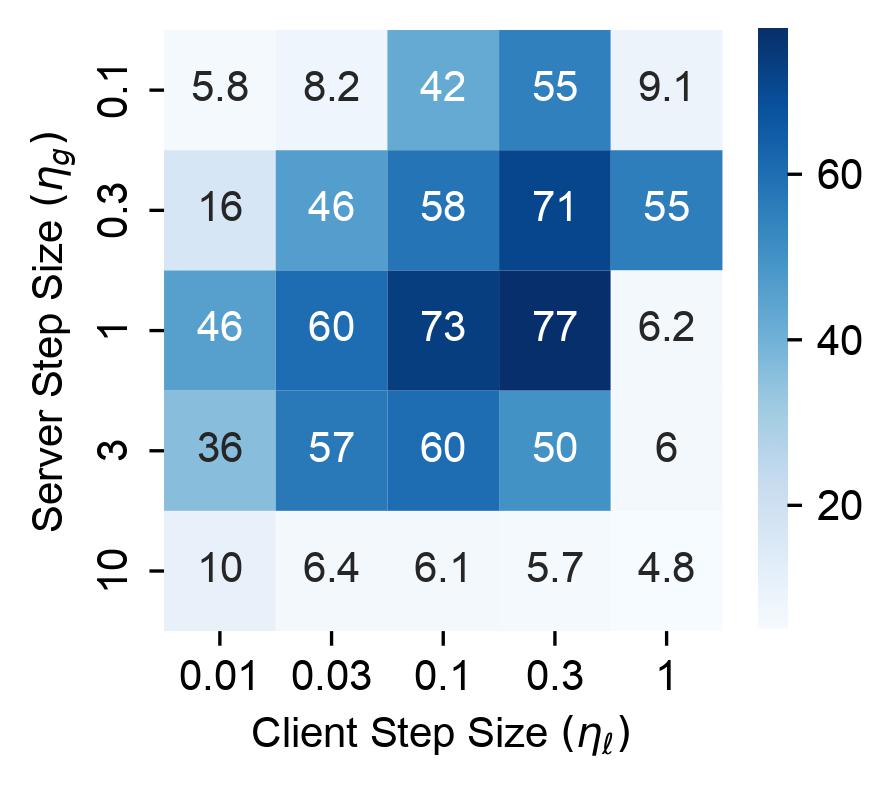
Divyansh Jhunjhunwala , Shiqiang Wang, Gauri Joshi International Conference on Learning Representations (ICLR), 2023 ( Spotlight, top 25% of accepted papers ) Develop FedExP, a method to adaptively determine the server step size in FL based on dynamically varying pseudo-gradients throughout the FL process. |
|
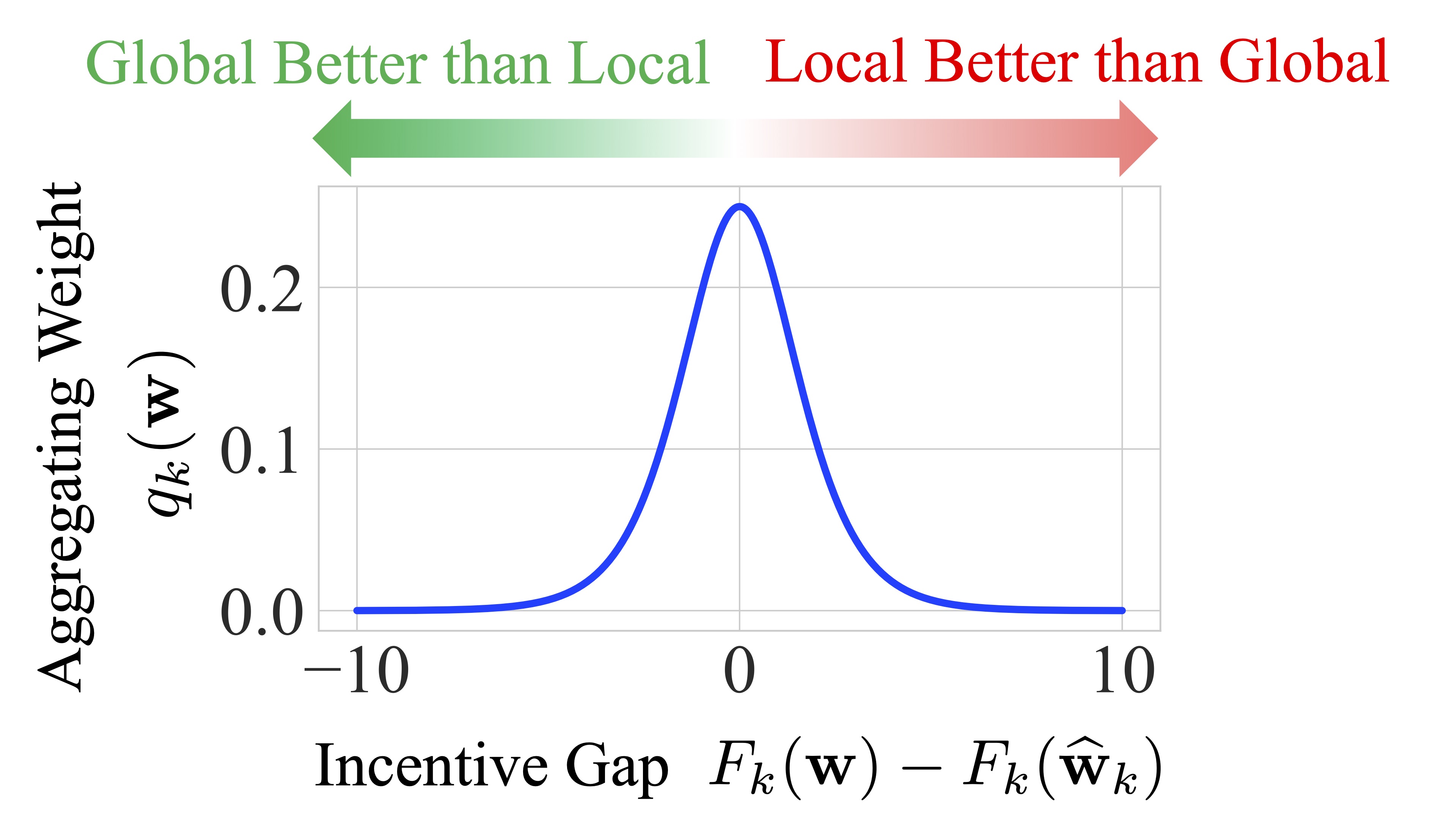
Yae Jee Cho, Divyansh Jhunjhunwala , Tian Li, Virginia Smith, Gauri Joshi Transactions of Machine Learning Research (TMLR), 2024 Propose MaxFL algorithm to explicitly maximize the fraction of clients that are incentivized to use the global model in federated learning. |
|
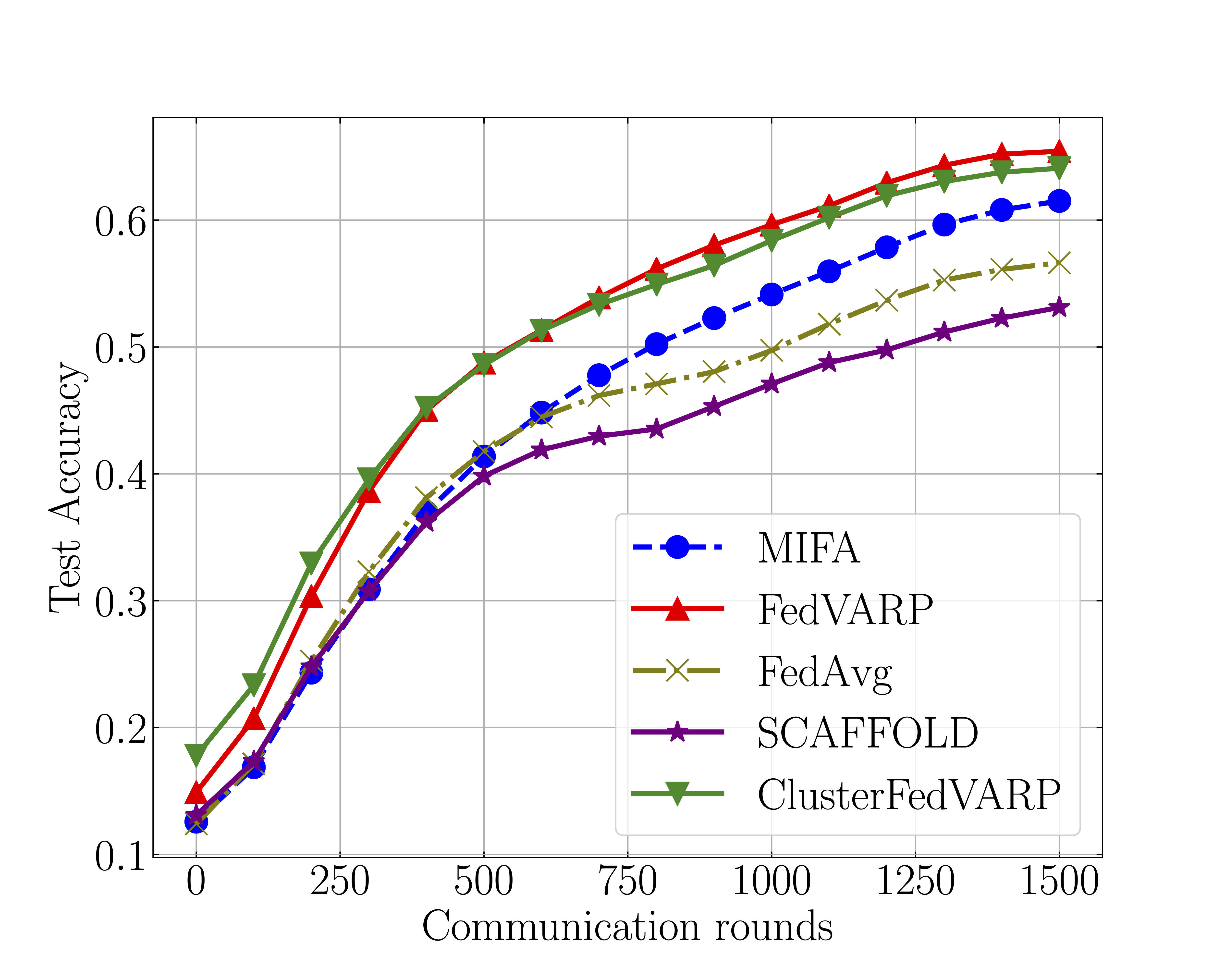
Divyansh Jhunjhunwala , Pranay Sharma, Aushim Nagarkatti, Gauri Joshi Uncertainty in Artificial Intelligence (UAI), 2022 Propose FedVARP algorithm to deal with variance caused by only a few clients participating in every round of federated training. |
|
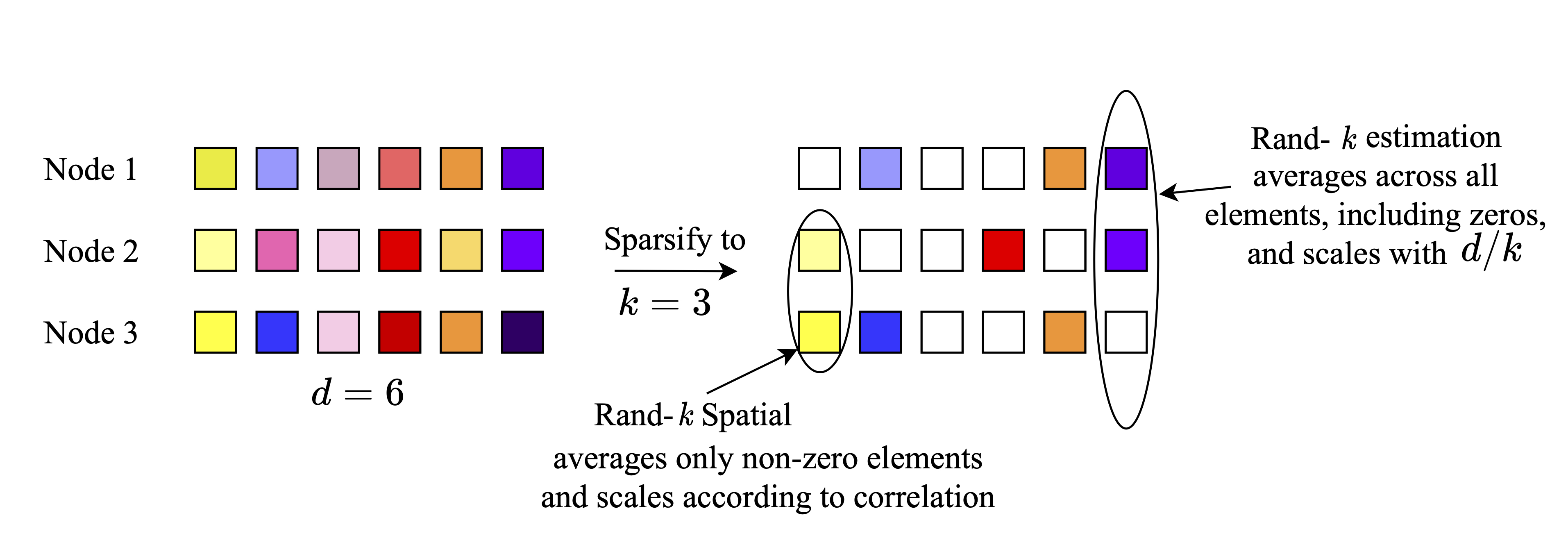
Divyansh Jhunjhunwala , Ankur Mallick, Advait Gadhikar, Swanand Kadhe, Gauri Joshi Advances in Neural Information Processing Systems (NeurIPS), 2021 Introduce notions of spatial and temporal correlations and show how they can be used to efficiently compute the mean of a set of vectors in a communication-limited setting. |
|
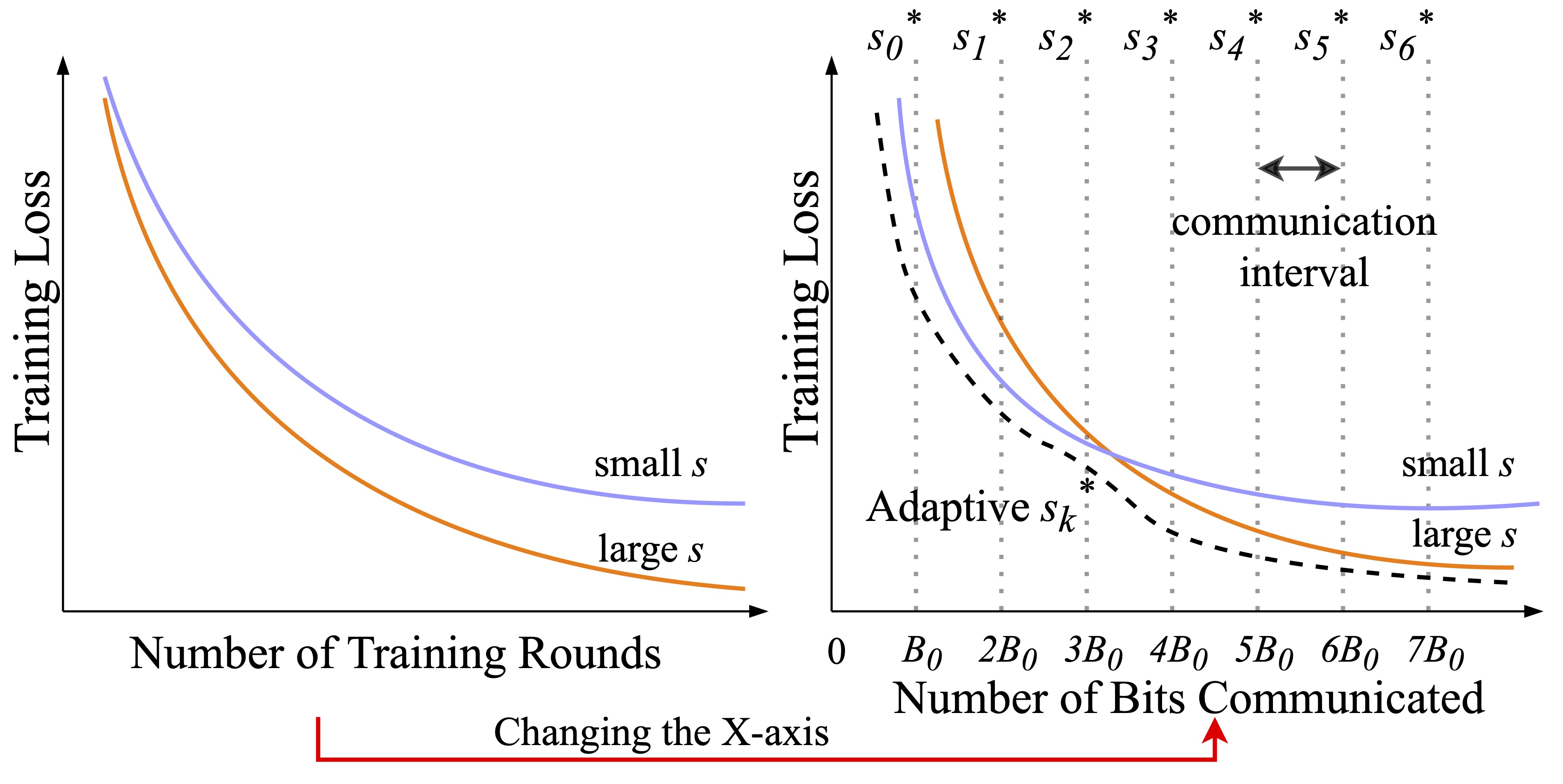
Divyansh Jhunjhunwala , Advait Gadhikar, Gauri Joshi, Yonina C. Eldar International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021 Propose an adaptive quantization strategy that aims to achieve communication efficiency as well as a low error floor by changing the number of quantization levels during training in federated learning. |
|
( * denotes equal contribution) Source code credit to Dr. Jon Barron. |